오늘은 저번 포스팅에 이어 팀 분석 프로젝트의 2번째 시간입니다.
해당 내용의 재밌는 이야기와 잡담, 꿀팁을 보고 싶다면 아래 링크를 클릭해주세요.
https://blog.naver.com/xodndxovnd/222856350092
6. [삼성 SDS Brightics] 팀 분석 프로젝트 2 텍스트 마이닝& 소비패턴분석 2차 팀 분석 프로젝트
안녕하십니까~ 오늘은! 저번 포스팅에 이어 팀 분석 프로젝트의 2번째 시간입니다!!!!!!!!! (참고로 3번째 ...
blog.naver.com
1. 개요

우리 브라잌! 팀의 주제는 앞 포스팅에서 이야기 했듯
MZ세대를 대상으로 한 카드 이용내역 및 소비패턴 분석
이 저희 팀의 주제입니다.
그리고 대상으로 하는 MZ세대는 바로 '저희 팀원들' 입니다.
팀원들 각자 주로 쓰는 카드 내역 1년치를 가져와서 시계열 분석 및 예측모델링을 해볼 예정입니다.
우리가 이 주제를 선정한 이유가 바로 개개인의 소비 패턴을 알아보고, 내가 직접! Brightics를 활용해 나의 카드 사용 내역을 손. 쉽.게. 따라해 볼 수 있게 하는게 목적이기에 이에 부합해서 실제로 우리의 데이터를 사용해 보기로 했습니다.
그리고 최근 트랜드를 파악할 수 있는 텍스트 마이닝(토픽 모델링, 텍스트 마이닝) 그리고
간단한 소비 내역 시각화 또한 함께 진행하며,
1. 오호~ 요즘 소비 관련 키워드들은 이런게 있구만..? - 텍스트 마이닝
2. 어! 내가 쓴 돈을 이렇게 손쉽게 시각화 한다고?!? - 간단 시각화
3. 그렇담! 요즘 내 친구들(혹은 나)은 돈을 어떻게 사용할까? 요롷게? - 시계열 분석 및 모델링
위와 같은 인사이트를 도출해 내기로 했습니다.
2. 사용 데이터 준비
1. 텍스트 마이닝
텍스트 마이닝에 사용할 데이터는 크롤링을 통해 가져왔습니다.
Brightics Studio 분석에 정말 특화된 프로그램입니다.
텍스트 마이닝 하면 대게 어떤 분석들이 떠오르시죠? wordcloud를 활용한 형태소 분석, 빈도분석, 토픽 모델링 정도가 떠오르실 겁니다.
그런데, Brightics Studio는 이에 더해 토픽 모델링 한 단어들을 정량적인 숫자로 정리하고, 회귀 분석, 분류, 예측을 통해 추가적인 분석이 손쉽게 가능합니다.
https://www.brightics.ai/kr/docs/ai/manual/tutorial/b19f13b94cc87c33.html#37211190a1771190
Brightics Studio 1.1 Tutorial
www.brightics.ai
튜토리얼에 따르면 정말 수 많은 텍스트 마이닝을 사용한 분석을 진행할 수 있습니다.
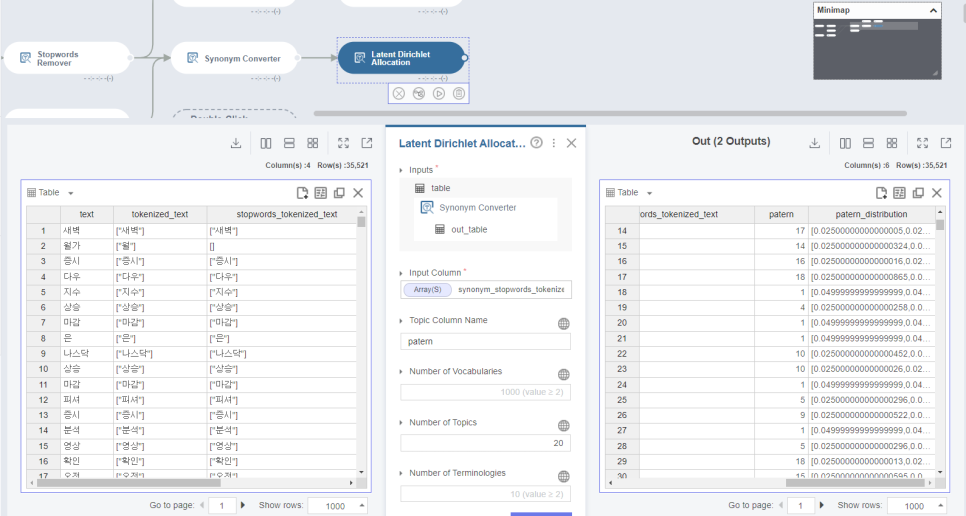
토픽 모델링을 진행하면, 해당 단어들이 어떤 '토픽 주제'에 연관 돼 있는지 patern컬럼명으로 번호를 매겨줍니다.
ex) 자산-1, 돈-1, 집-2, 부동산-2
그리고 해당 패턴의 분포를 patern_distribution을 이용해 정량적으로 나타내줍니다.
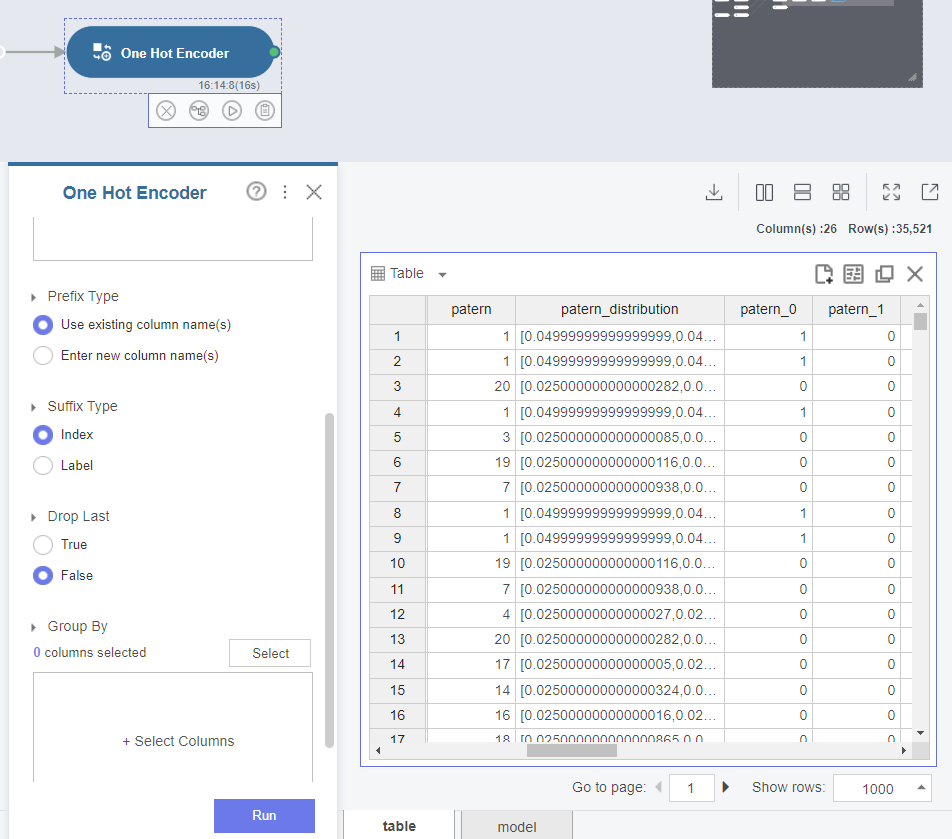
그리고 이를 one hot incoding을 통해 유효한 variable 값으로 변경해주고,

회귀분석을 통해 어떠한 '내용'이 ex)매출과 연관이 있는가? 와 같은 분석을 진행할 수 있습니다.
결론적으로 저는 형태소 분석과 토픽 주제들만을 알아보기 위해 간단하게 분석을 진행하기 위해서, 하나의 컬럼으로 이루어진
'소비 패턴'으로 검색 된 기사를 크롤링해와 분석을 진행합니다.
2. 간단 시각화
간단 시각화는 바로
서울특별시 빅데이터 캠퍼스
bigdata.seoul.go.kr
서울특별시 빅데이터 캠퍼스에 있는 '서울시민의 업종별 카드 소비 패턴 데이터'를 활용해 어떤 소비 패턴을 보이는지 시각화합니다.
(필자는 텍스트 마이닝을 맡았고, 저희 팀원 4명이 해당 데이터를 시각화하기로 했습니다. 해당 포스팅을 보고 싶다면 아래 링크를 클릭해 주세요.)
밍구의 밍기적 일상 : 네이버 블로그
안되면 되는거 해라
blog.naver.com
https://blog.naver.com/gaeuny0604/222850066904
[Brightics 서포터즈] 팀 분석 프로젝트 #1 주제선정 - MZ세대 소비패턴 분석
안녕하세요! Brightics 서포터즈 3기 남가은입니다. 굉장히 오랜만에 글을 쓰는 것 같아서 마지막으로 쓴 ...
blog.naver.com
https://blog.naver.com/yyyasss/222849986750
[Brightics] Ep5. Brightics 팀 프로젝트 첫 시작: 주제 선정
안녕하세요! 이번주부터 '삼성SDS 브라이틱스 서포터즈 3기' 의 팀 프로젝트가 시작했습니다....
blog.naver.com
https://blog.naver.com/mipi1001/222849697054
[Brightics Studio]팀 분석프로젝트 #1-1: MZ세대 소비패턴 분석-주제선정
안녕하세요! 오랜만에 돌아온 Brightics 서포터즈 포스팅입니다~ 개인프로젝트 포스팅 이후 약 한달만이네...
blog.naver.com

해당 사이트에 접속하면 위와 같이 자료를 받을 수 있습니다.
각각
1. 성별, 연령, 지역별로 어디에 얼마나 카드를 사용하는지
2. 시간대 별로 전체 카드 이용 금액, 소액 결제 건수를
3. 지역, 업종별로 전체 카드 이용 금액, 사용 횟수를
4. 업종, 시간별로 전체 카드 이용 금액, 사용 횟수를
보기 쉽게 서울 시민들이 위 항목들로 어떤 소비 패턴을 갖고 있는지 시각화 합니다.
3. 시계열 분석 및 모델링
위에서 언급한 것과 같이 팀원들의 카드 소비 내역을 만져서 '시계열 분석 및 모델링'을 진행합니다.
필자의 주거래 통장은 카카오뱅크입니다.
카카오뱅크는 본인 통장 및 카드 사용 내역을 Excel 파일로 받아 볼 수 있는 서비스를 제공하고 있습니다.
(이는 다른 카드사들 또한 동일합니다.)
(모바일 기준) 본인 통장 누르기-> 관리 ->거래내역->파일을 받을 이메일 입력

그러면 위와 같은 창이 뜹니다. 내가 원하는 기간을 설정하고 다음을 누르면
이렇게 바로 메일이 날라옵니다.
참고로 저희 팀은 작년 1년동안 MZ세대들(우리 팀원들)이 어떤 소비 패턴을 갖고 있는지 알아보기 위해
2021-01-01 ~ 2021-12-31의 내역을 갖고 왔습니다.

이렇게 카드 거래 내역을 가져오는데,
생각보다 고려할 사항들이 많습니다.
내가 내 계좌로 돈을 보냈다던가, 다시 뻈다던가 등등
저는 필터를 걸어 입금 내역은 전부 지워 버리고, 출금 내역만 남기고, '내용' 컬럼 데이터들을
|
전자상거래(결재대행)
|
|
|
의류/잡화
|
|
|
요식/유흥
|
|
|
교통/자동차
|
|
|
스포츠/문화/교육
|
|
|
레저/여행
|
|
|
미용
|
|
|
유통/음,식료품
|
|
|
기타
|
위 표와 같이 팀원과 협의 후 업종을 선정하여 새로운 컬럼을 만들었습니다.
이렇게 이제 모델링 준비는 끝
(전처리 과정은 다음주 포스팅에 한번에 보여드리겠습니다.)
3. 텍스트 마이닝(분석)
자 지금부터 '소비 패턴'에 대한 텍스트 마이닝을 통해 현재 시장의 동향을 파악해보도록 하겠습니다.
우선 데이터를 load합니다.
(자세한 load 방법은 첫번째 포스팅 참조 부탁드립니다.)
여기서 잠깐. 여지껏 Brightics Studio를 사용하면서 한글로 이루어진 파일을 올리면 raw데이터 글자들이 깨지는 현상을 아래와 같이 목격해 왔을 것입니다.

제가 시도해 본 바, 해결 할 수 있는 방법이 두가지 있습니다.
기본적으로 Excel 파일을 load한다는 가정하에 설명 드리겠습니다.
첫 번째

불러올 or 아무 엑셀 파일을 엽니다. 이후 상단 툴바에서 데이터 -> 텍스트/csv에서를 클릭
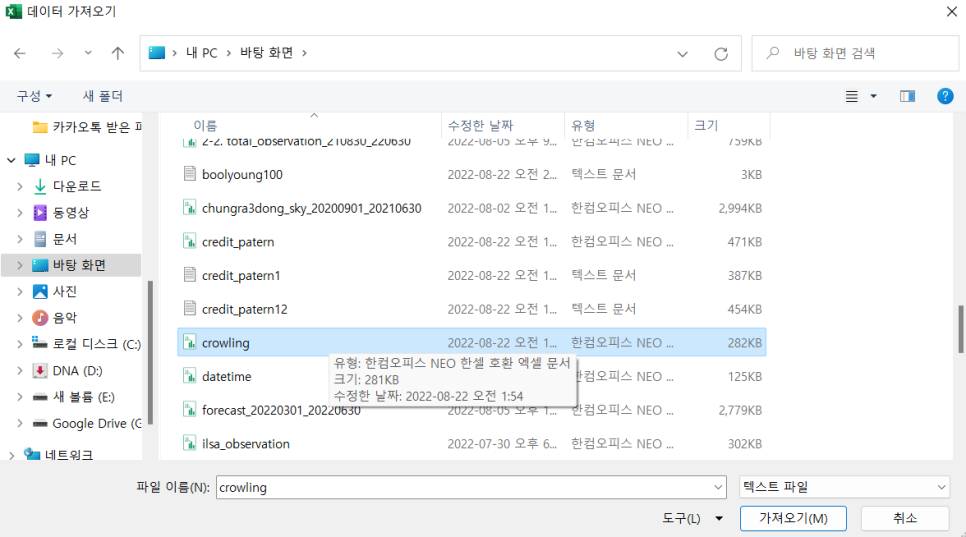
바로 가져오기 창이 뜨는데, 불러와야하는 파일을 가져와줍니다.
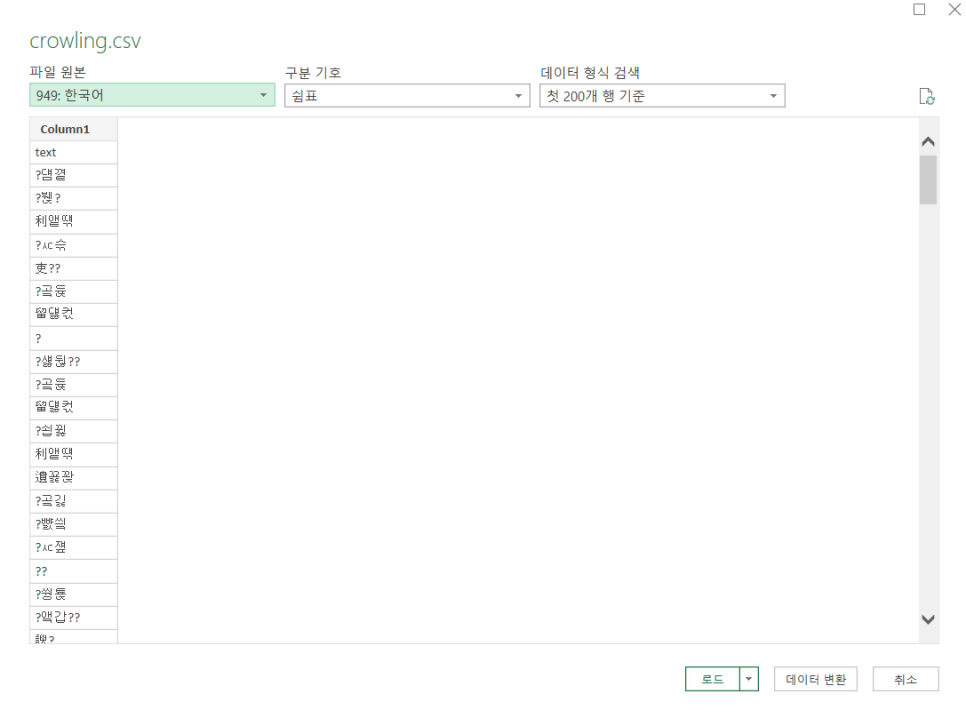
그러면 이런 창이 뜨고, 왼쪽 상단에 949: 한국어로 표시 돼 있을 것입니다.
저걸 바로
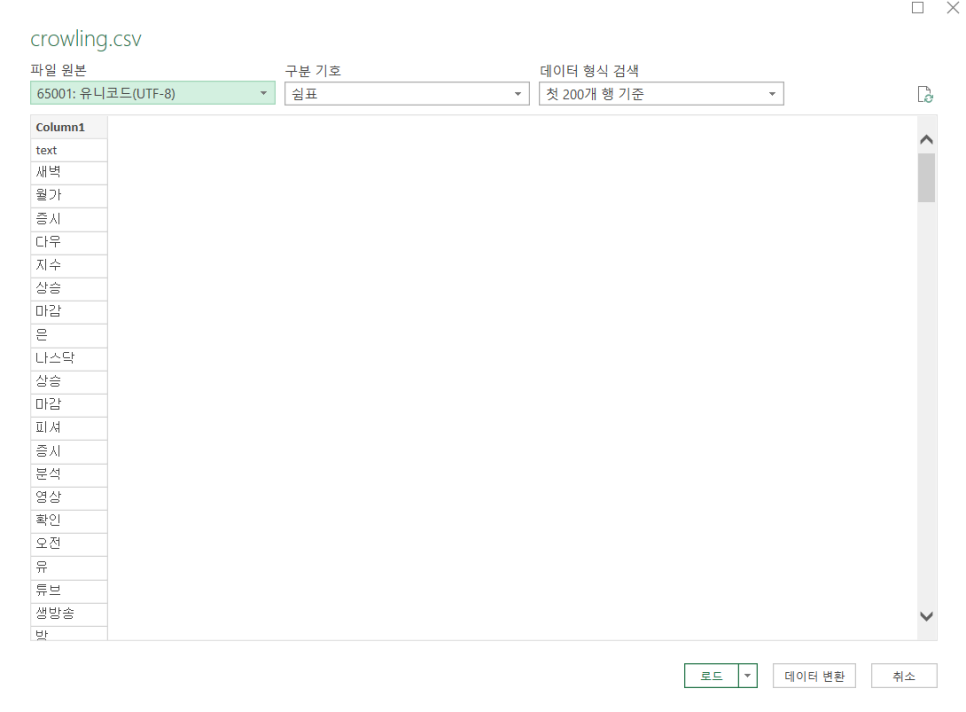
65001: 유니코드(UTF-8)로 변경해주면?
짜잔! 정상적으로 파일을 읽어오는 모습을 보여줍니다.
(UTF-8) 코딩할 때 파일 불러오면서 한글 깨짐으로 많이들 집어 넣던 코드 중 하나입니다.
바로 로드 버튼 누르고 저장하면 끝
두 번째
다음 두 번째 방법은 바로, 텍스트 파일로 변환 후 인코딩하는 방법입니다.
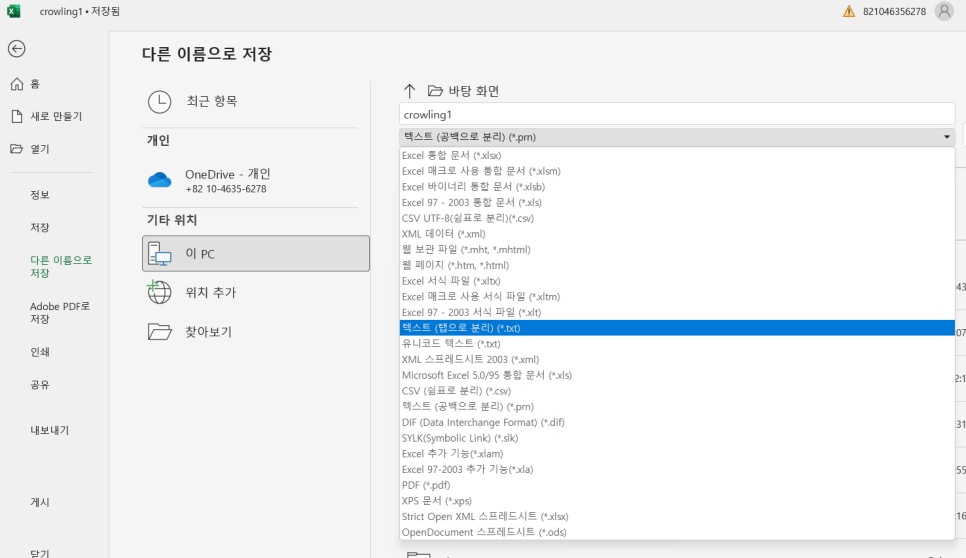
다른 이름 저장을 누르고, 텍스트(탭으로 분리) (*txt)를 설정해 저장해 줍니다.
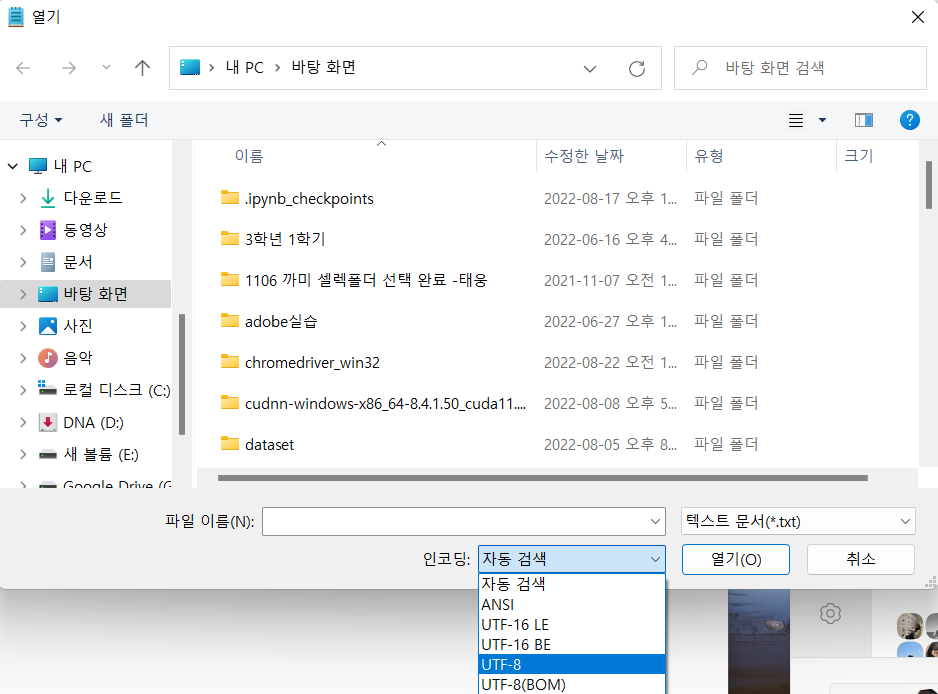
다음으로 해당 파일 or 새 메모장을 열어 파일->열기를 눌러 해당 창을 열고,
인코딩 부분에서 UTF-8을 클릭해 열기를 눌러주면
정상적으로 한글이 읽히는 것을 보실 수 있습니다.
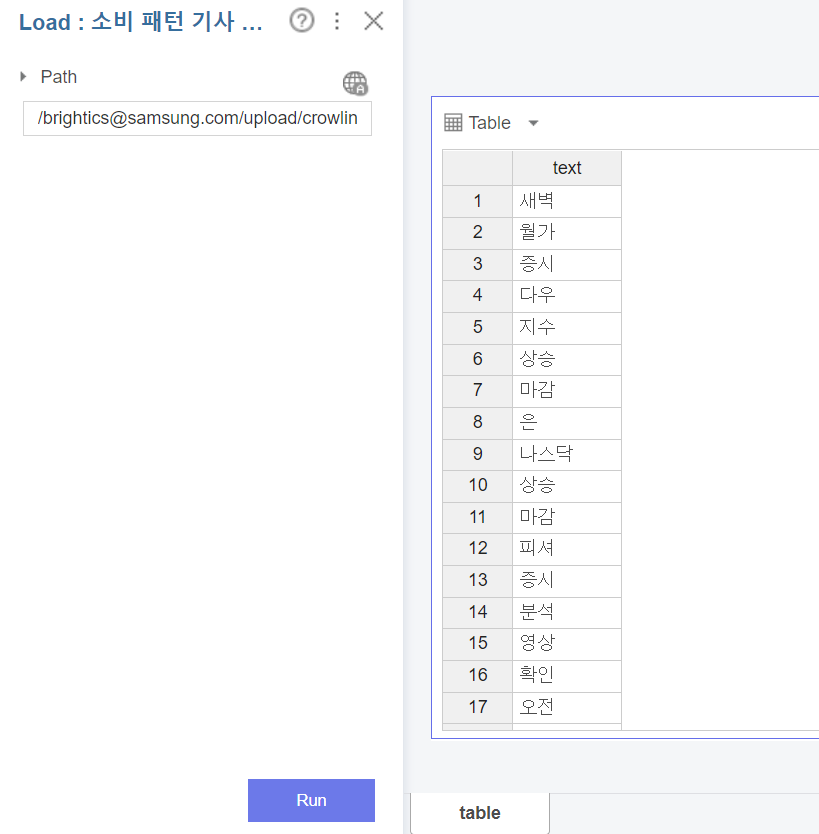

다음으로 Tokenizer (Korean)을 불러와 줍니다.
파이썬으로 형태소 분석을 진행해보신 분들은 konlpy라고 잘 알고 계실 겁니다.
바로 '한국어 처리 패키지'입니다. 파이썬에서는 설정할 것도 많고, 실패하는 경우도 꽤나 생깁니다.
해당 기능은 문장에서 필요한 품사들만을 추출해주는 기능을 담당합니다.

이렇게 굉장히 여러가지 품사들을 불러와 줄 수 있습니다.
저는 제일 기본이 될 수 있다 하는 명사, 동사, 형용사, 부사(Noun, Verb, Adjective, Adverb)를 뽑아 와 보겠습니다.
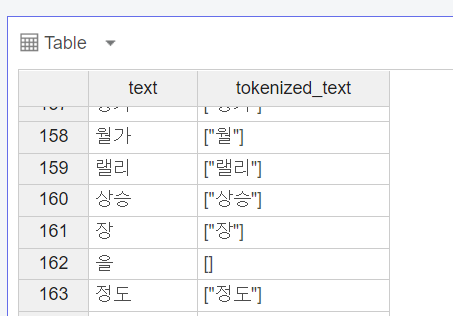
그러면 이렇게 'tokenized_컬럼명'을 생성하며, 설정한 품사들만을 불러와 줍니다.

보시는 것과 같이 '을' 이라는 조사가 제외됐습니다.
다음으로 '불용어 제거' 를 해보겠습니다.

Stopwords Remover는 토크나이저를 통해 얻은 단어 중 내가 가져가고 싶은 '주제'와 너무 크게 동떨어진 단어들을 제거해주는 함수입니다.
스탑워드 리무버 함수를 사용하려면,
Create Table을 하나 생성해줍니다.

그리고 Open Editor를 클릭해

이렇게 삭제할 단어들을 테이블에 집어넣어주고 스탑워드 리무버 함수에 연결해줍니다.
그리고 인풋 컬럼스에 'tokenized_컬럼명'을 넣고 실행시켜주면

함수명이 함께 붙어 'stopwords_tokecized_컬럼명'이라는 새로운 컬럼을 생성하고, 필요없는 단어들을 제거해준 모습을 확인할 수 있습니다.
그러면, 토픽 모델링을 해보기 전에 형태소 분석을 통해 많이 나온 단어들을 빈도 순서대로 이쁘게 시각화 시켜줘 봅니다.

위 사진과 같은 방법으로 시각화를 진행합니다.
빈도가 큰 만큼, 해당 단어도 크게 도출시켜 줍니다. 그러니 '빈도 분석'을 진행하겠습니다.
Bag of Words 함수를 불러와 줍니다.
백 오프 워드 함수는 앞에서 전처리 시킨 토큰화된 단어들의 빈도를 파악해주는 함수입니다.
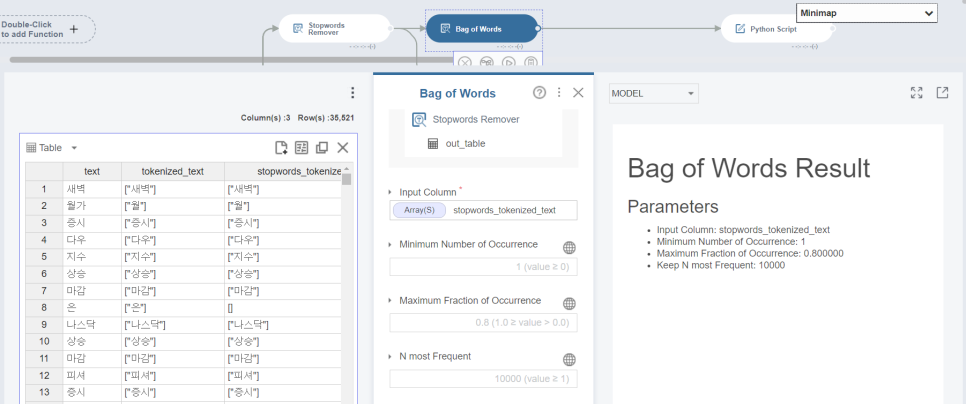
이렇게 마지막에 토큰화시킨 'stopwords_tokenized_컬럼명'을 인풋 시키면
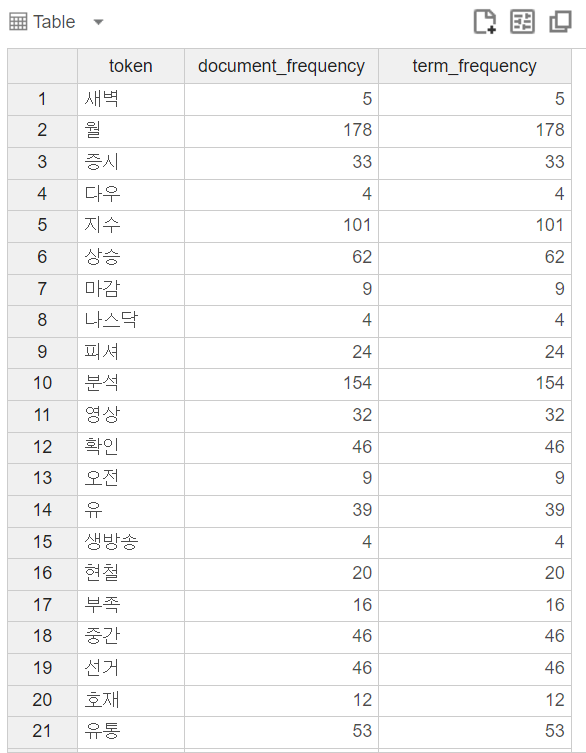
단어들의 빈도수를 확인할 수 있습니다

다음으로 Python Script 함수를 사용합니다.
import pandas as pd
import os
import matplotlib.pyplot as plt
from wordcloud import WordCloud
df = pd.DataFrame(inputs[0])
key_ = list(df['token'])
value_ = list(df['document_frequency'])
df_list = dict(zip(key_, value_))
wordcloud_ = WordCloud(background_color="white", width=800, height=800,
font_path="C:/Users/SDS/AppData/Local/Microsoft/Windows/Fonts/NanumGothic.ttf").generate_from_frequencies(df_list)
plt.figure(figsize=(25,25))
plt.imshow(wordcloud_, interpolation='bilinear')
plt.axis("off")
plt.show()
해당 코드를 입력해주고
이름을 plt, 그리고 IMAGE를 클릭해줍니다.
그 다음 런을 해주면


.. 금방 해결해보겠습니다.
<3. 텍스트 마이닝 + 시계열 분석 및 모델링은 다음 포스팅에 이어집니다>
※해당 포스팅은 Brightics 서포터즈 할동의 일환으로 작성되었음을 알립니다.



