
이번 시간에는 저번 텍스트 마이닝을 끝내고! 예고 했던 시계열 분석에 대해서 포스팅하려합니다.
수다스런 저의 다른 포스팅을 보고 싶다면 아래 링크를 참고 부탁드리겠습니다.
https://blog.naver.com/xodndxovnd/222866960373
8. [삼성 SDS Brightics] 팀 분석 프로젝트 4 시계열 분석 2차 팀 분석 프로젝트
안녕하십니까~ 다들 잘 지내셨나요?? (아뇨~) 에이~ 왜그래요! 그래도 평소보다 빨리왔는데? (아니 더 빨리...
blog.naver.com
1. 시계열 분석 개요
시계열 분석 이란?
시간에 대해 순차적으로 관측 되는 데이터를 활용해 분석을 하는 것.
데이터를 분석할 때는 대게 독립변수를 이용해 종속변수를 예측하거나, 제가 좋아하는 회귀분석 같은 경우 독립변수가 종속변수에 영향을 끼치는가? 와 같이 변수들을 활용합니다.
시계열 분석에서는 이 독립변수를 바로 '시간'을 사용한다고 생각하시면 됩니다.
시계열 분석은 시간의 패턴을 분석 및 분류, 미래 어떠한 시점을 예측하는데 사용됩니다.
최근 기술의 발전으로 굉장히 여러 예측 및 분석 모델들이 만들어졌지만, 저는 전통적인 분석 방법인 ARIMA 모델을 활용해 분석 및 예측을 진행해 볼 예정입니다. 사실 정확히 말하면, MA, EWMA 모델 비교이고, 차후 이어지는 ARIMA 모델은 다른 팀원이 모델링을 진행합니다.
ARIMA 모델에 대해서 간단히 설명 드릴게요
2. 모델 설명
ARIMA 모델이란?
현재 시점의 상태를 파악하는 과거 시점의 <1.자기 자신>과 <2.추세>까지 전부 반영하며, <3.차분>이라는 개념을 사용해 비 정상성(non-stationary)의 상황에서 더 좋은 예측을 할 수 있는 모델을 말합니다.
자! 사실 저는 그래서 Brightics로 분석을 어떻게 하냐?를 여러분께 알려주는게 목적이니 너무 자세한 설명은 생략하겠습니다.
그렇다면, 거꾸로 개념만 잡아보고 갑시다.
1. AR 모델
<자기 회귀 모델> = <1.자기 자신>
AR모델은 자기 회귀 모델이라 불립니다. 과거 자기 자신의 데이터가 현 시점의 자기 자신에게 영향을 미치는 모델이라는 뜻.
2. MA 모델
<이동 평균 모델> = <2.추세>
MA 모델은 이동 평균 모델이라 불립니다. 추세가 변하는 상황에서 사용하기 딱 좋은 모델이라는 것.
자 여기까지 들으면 뭔가 감이 오실 겁니다. 맞습니다.
ARIMA 모델은 [<자기 회귀 모델> = <1.자기 자신>] + [<이동 평균 모델> = <2.추세>]
두 모델을 합친 것입니다.
마지막 + <3. 차분>이라는 개념까지 합한 모델인 것이죠.
차분의 간단한 개념은 아래와 같습니다.

이게 바로 정상성을 갖는 데이터의 모습

이게 비 정상성을 갖는 데이터의 모습입니다.
당연히 이렇게 비 정상성을 갖는 데이터로 시간의 흐름을 통한 어떠한 분석 인사이트를 내놓을 수 없습니다.
그래서 바로 이전 값을 빼주며 정상성을 가진 데이터로 만들어주는 과정을 거치는 겁니다.
그럼 사용할 수 있을 뿐더러, 분석 성능, 예측 능력도 올라가는 것이죠.
한마디로 여러 기법을 활용해 가장 최적의 성능을 갖고, 전통적인 시계열 분석 모델이라 생각하면 끝입니다.
저희는 데이터가 사실 그닥 많지 않고, 데이터의 패턴이 크게 없을 것이라 판단하기도 했기 때문에 ARIMA 모델을 채택한 것입니다.
기본적으로 많은 분들이 개인의 카드 사용 내역을 분석할 수 있는 방법을 알려드릴 수 있는 성능 최적의 모델을 생각해보니 해당 ARIMA가 좋겠다고 판단한 것이지요.
그래도
바로 ARIMA로 건너뛰기에는 좀 석연치 않기 때문에, 약한 정상성을 만족한다 가정하는 MA모델을 한번 돌려 결과를 확인해 보기로 했습니다.
개인 카드 내역은 '과거의 충격이 현재의 결과에 영향을 주는 경우'가 될 수 있다고 판단했고 정상성 문제에 대해서 자유롭기에, 쉽게 이해도, 따라해볼 수도 있는 경우이니깐 말입니다.
+
추가로 EWMA
EWMA는 바로 <지수 가중 이동 평균>이라 합니다. 조금 특수한 시계열도에 사용하는 모델이죠. MA를 조금 다른 방향으로 발전 시켰다고 보면 됩니다.
단지 '추세'만 판단 하는 것이 아닌, 지난 모든 부분군 평균들에게 지수적으로 감소하는 가중치를 부여한 가중 평균을 타점합니다. 그렇기 때문에 더 작은 평균 변화를 감지하는데 활용할 수 있습니다. (제가 사용하려는 데이터는 엄청 작은 평균 변화를 갖고 있죠 카드 데이터는 하루에도 10원 단위로 사용 금액이 변경되기도 하니깐)
그렇기에 우선적으로 우리가 사용하는 개인 카드 내역을 ARIMA 모델로 분석 및 예측을 해보기 전에
초석 다지기로 MA, EWMA 모델을 비교해보는 것입니다.
3. MA, EWMA 모델 비교
서론이 길어졌습니다. 그러니
Brightics를 활용한 분석 바로 진행해보도록 하겠습니다.
저희는 거래 일시, 이용금액 2 컬럼이 필요한 상태입니다. 그리고 날짜별로 모든 가격들을 합해버렸죠.
이때 Python Script를 활용했습니다.

import pandas as pd
df1 = inputs[0]
df2 = inputs[1]
df3 = inputs[2]
df4 = inputs[3]
df5 = inputs[4]
df = pd.concat([df1, df2, df3, df4, df5])
다음과 같은 코드를 활용해 같은 시간에 있는 모든 이용 금액들을 더해줬습니다.

다음으로 Select Column을 이용해 거래일시, 이용금액 컬럼만을 남겨 놓습니다.
이 때 엄청 높이 치솟은 이용 금액을 확인할 수 있습니다.
저런 값은 우리가 분석하고자 하는 방향에 큰 문제가 될 수 있으니, 이상치로 생각하고, 대략적으로 평균 값들이 가진 값으로 짤라버립시다.
네 이상치 처리입니다.

20만원 이하의 값으로 Filter 함수를 걸어 이상치 제거를 진행해줍니다.
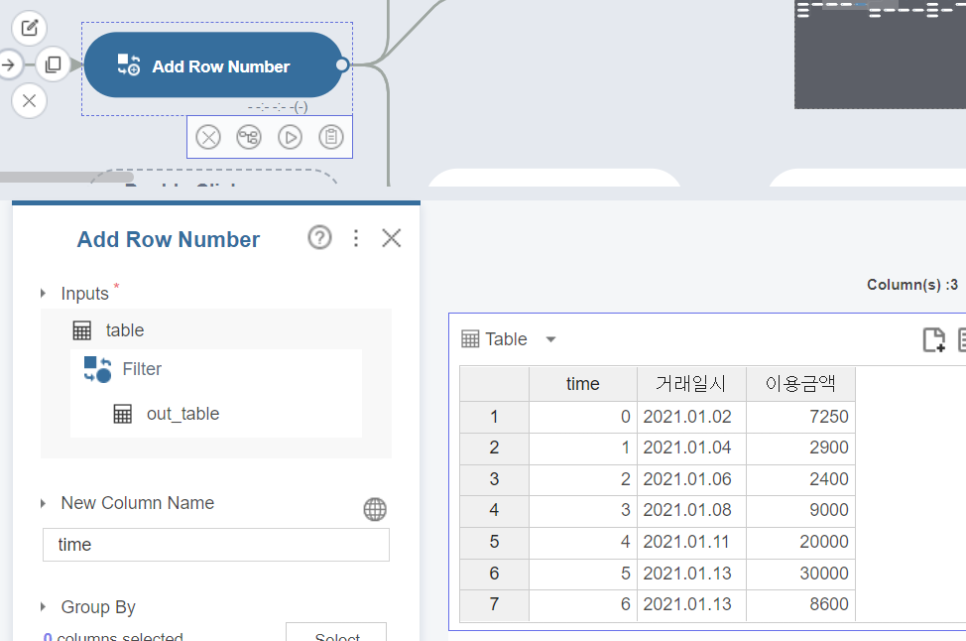
다음으로 Add Row Number 함수를 활용했습니다.
그냥 이거 단순히 행에 1, 2, 3, 4 붙혀 시간의 흐름을 확인할 수 있게 해주는 함수입니다.
이렇게 데이터 전처리는 끝입니다.
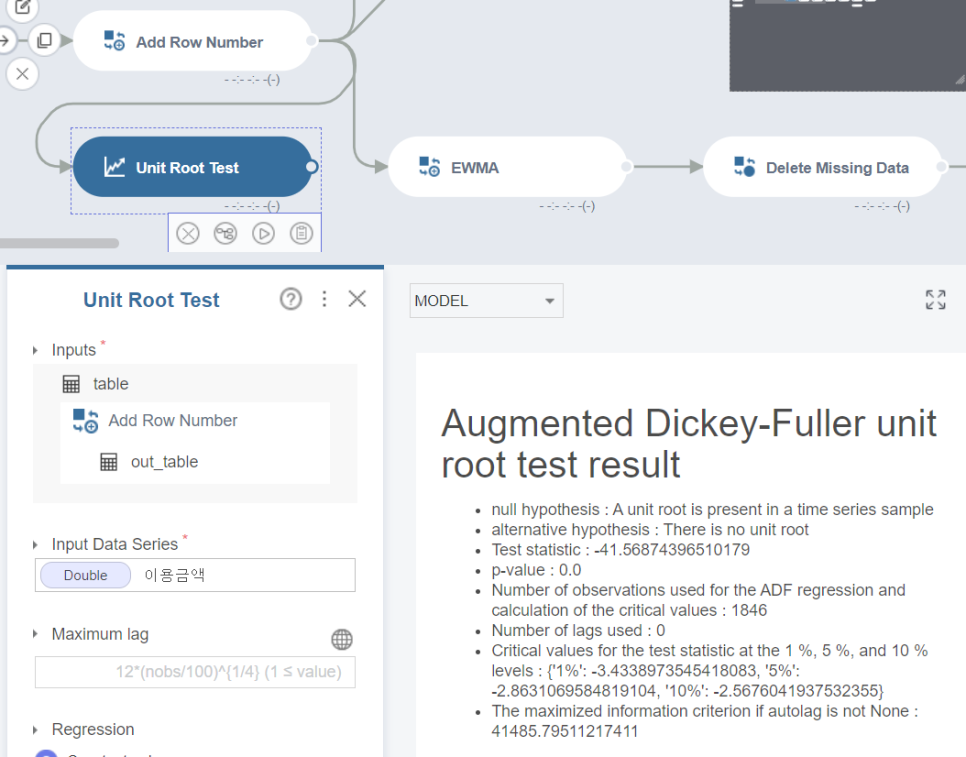
다음으로 Unit Root Test 함수를 활용해 정상성을 확인해 봅시다!
MA모델에서는 확인할 필요는 없지만, 위에 설명한 개념에 대해 간단히 짚고 넘어가고자 확인 방법을 서술했습니다.
다른 팀원이 진행할 ARIMA 모델링에서 전반적인 프로세싱을 다루고 있으니 확인 부탁드립니다.
p-value 값이 0.0으로 정상성을 만족 하는 결과를 보여주고 있습니다.
(이에 대한 정확한 프로세싱은 맨 아래 링크 걸어둔 다른 팀원의 글을 확인해 주세요~)

MA 모델링 과정입니다.

EWMA 모델링 과정입니다.
입력 함수 말고는 다 똑같다는 것을 알 수 있습니다.

Moving Average 함수에서 Window Size는 2를 두고 Run을 눌러 새로운 컬럼을 만들어줍니다.
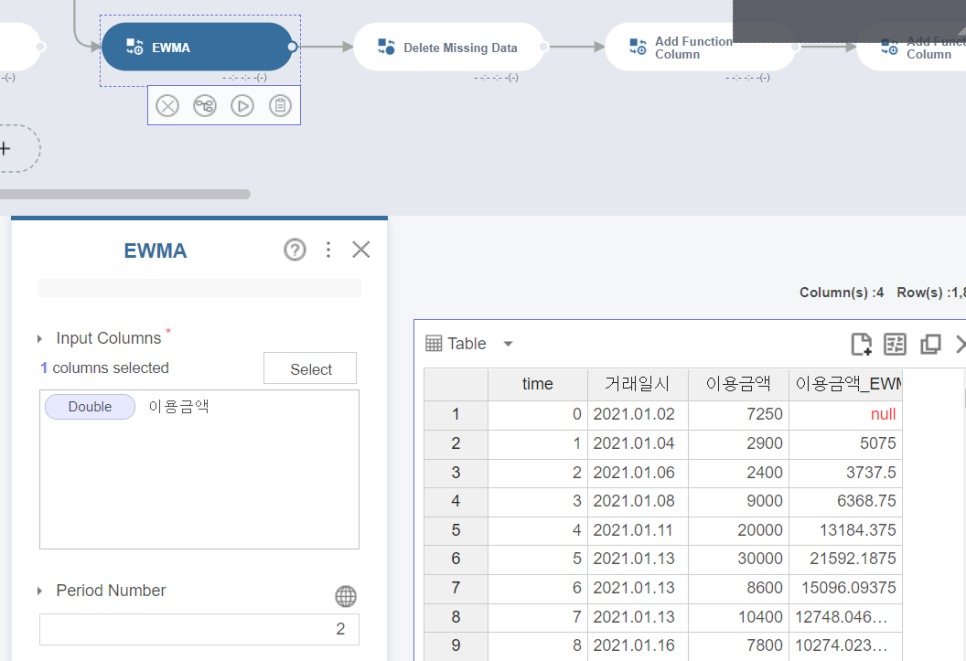
EWMA 함수에서 Period Number을 2로 두고 Run을 합니다.
자자 Window Size는 Period Number와 같은 하이퍼 파라메터 튜닝이라 보면 됩니다. 사실 계절성, 주기성이 있다면 그에 맞게 ex) 주간 간격을 보인다? 7을 설정하면 됩니다. 하지만 딱 보기에도 그런거 없습니다. 해당 하이퍼파라메터를 조정하는 것에 따라 결과가 크게 차이가 나는데, 딱히 시간별 패턴이 보이지 않으니 둘다 2로 설정합니다.
같은 수로 두어야 두 모델을 비교할 수 있기 떄문에 둘다 2로 설정합니다.
2번째 EWMA 사진을 보면 새로 생성된 컬럼에 1번 컬럼은 NULL값을 갖고 있는 것을 볼 수 있습니다. 이게 바로 직전 날의 쇼크!를 분석에 활용하는 과정이라고 볼 수 있습니다. 파라메터를 7로 두면 7칸이 NULL값으로 변하면서 1주일 전의 데이터를 활용해 분석을 하는 것입니다.
이 다음부터는 두 과정이 같습니다. 검증 과정이거든요.
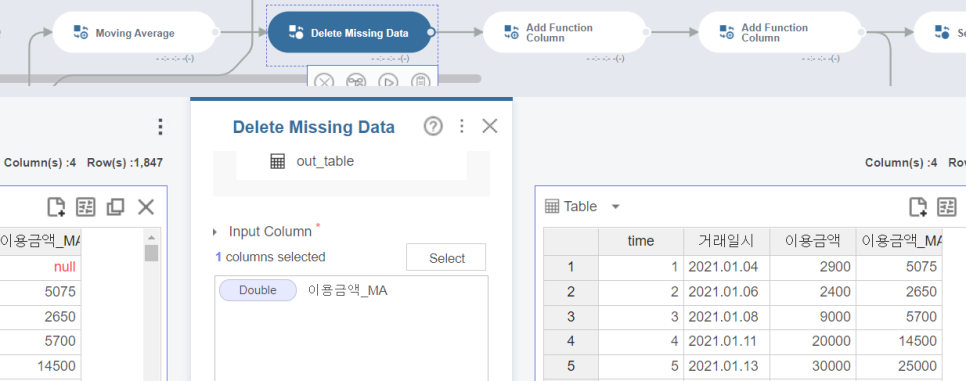
이전에 생성된 칼럼에 있는 NULL값을 Delete Missing Data함수를 활용해 없애줍니다.

다음으로 MSE(평가 지표) 값을 확인하기 위해 Add Function Colmn함수를 활용합니다.
(abs(이용금액-이용금액_MA))**2

한번 더 해당 함수를 활용해 MAPE 값을 구해줍니다.
abs(이용금액-이용금액_MA)/이용금액*100

MA 모델
MSE : 약 219576592
MAPE : 약 226

EWMA 모델
MSE : 약 148616257
MAPE : 약 239
MA값의 MSE(평가 지표)가 조금 더 낮은 것을 확인할 수 있습니다. (낮은게 좋은 것) 그럼 대강 MA모델이 더 좋은 결과를 가져온다는 것을 미리 알 수 있습니다.

다음으로 Select Column함수를 활용해 딱! time과 이용금액 Column만 남겨 봅시다.
그리고 Add Function Column:MA, Add Function Column:EWMA
함수들을 활용해 모델들을 비교해볼 수 있게 네임 코드를 각각 달아 둡니다.


MA, EWMA 모델도 완성 됐으니, 실측값과 비교해 봐야합니다.
전처리가 완료된 Add Row Number함수에서 Select Column 처리를 하여 time, 거래일시, 이용금액 컬럼만 가져와봅니다.

마찬가지로 실측값도 비교할 수 있게 같은 Add Function Column:actual 함수를 활용해 같은 형태로 변환해 줍니다
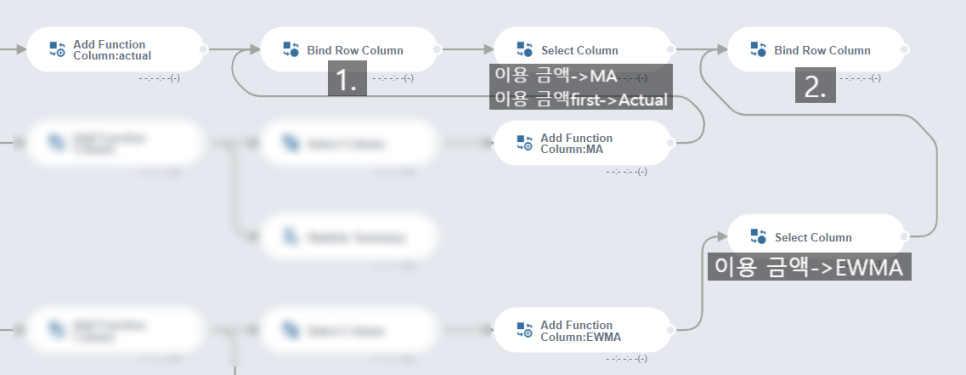
이후 Bund Row Column함수를 위와 같이 2번 사용 하여 3개의 모델을 하나로 합쳐 냅니다.
이 때 Select Column을 활용해 각 이용금액을 모델 별 이름으로 컬럼명을 변경해줍니다.
(모든 Bund Row Column함수의 Row or Column은 Column을 선택해 줍니다)
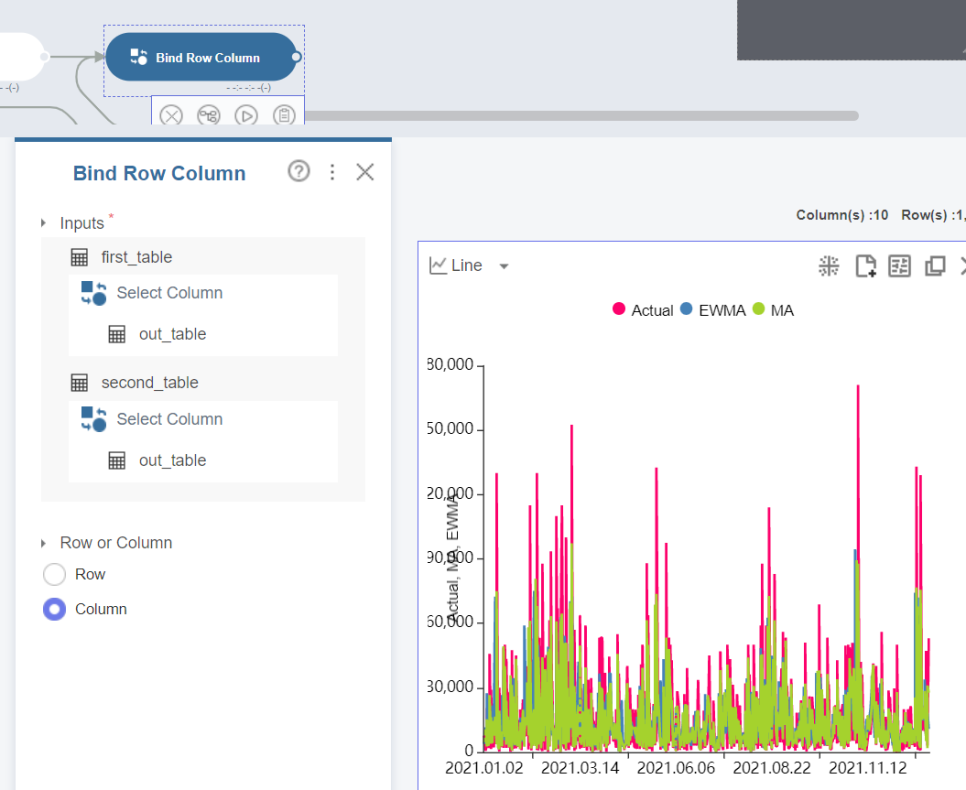
실측값, MA, EWMA의 모델 결과 비교가 가능해집니다.
조금 확대해서 확인해 보겠습니다.

전체적으로 실측값인 '빨간선'에 가장 가까운 값을 보이는 것은 초록색인 'MA'모델인 것을 확인할 수 있습니다.
중간에 평가지표로 확인 한 MSE 값을 보고 MA가 잘 나올 것이다 라고 추론했는데, 정답임을 알 수 있습니다.
결론적으로 개인 카드 내역을 활용한 시계열 분석 모델을 만드는데 MA와 EWMA 모델 중 MA 모델이 더 정확한 결과를 도출해내는 것을 알아 냈습니다.
아마 이런 결과가 나온 것은 EWMA 모델이 처음에 중심이 있다고 가정 하고, 값이 중앙에서 약간 벗어날 경우를 찾아내는 그런 민감도를 갖고 있어서 인 것 같습니다. 제가 가져온 데이터가 중앙이 있다고 판단 했더라도, 아래로는 정확히 막혀있고, 위로 20만원 이내 필터링을 두고, 데이터의 분포가 거의 이를 넘어가지 않는 선에서 고루 분포해 있기 떄문에 MA모델의 성능이 더 좋지 않았나 싶습니다.
4. 마무리
이렇게 제가 이번 팀 분석 프로젝트에서 맡은 역할은 모두 마쳤습니다. 짧으면 짧았지만, 길면 길었던 과정이었어요
정확한 인사이트 인지도 조금 걱정이 되지만, 너도 사용할 수 있다!를 알리는 것이 제 목표니까요.
저도 여러분도, 이렇게 한걸음 한걸음 더! Brightics를 활용하여 멋있는 분석가로써 함께 나아가 보면 좋을 것 같습니다.
시도를 하는 것과 머무는 것은 천지차이잖아요?
이후 내용인 ARIMA 모델 과정은 아래 팀원의 포스팅 확인 부탁드립니다.
다음 포스팅은 저희 분석 프로젝트 주제에 대한 프로포저, 그리고 결과에 대해서 서술하는 팀 분석 프로젝트 마지막 포스팅이 나갈 예정입니다.
그리고 다음 포스팅을 기점으로 영상 제작에 돌입하니 제작할 영상에 대해서도 큰 관심 부탁드립니다.
기대 많이 부탁드리며, 오늘은 여기까지 글을 마치도록 하겠습니다.
※해당 포스팅은 Brightics 서포터즈 할동의 일환으로 작성되었음을 알립니다.



