안녕하십니까. 삼성 SDS Brightics 3기 서포터즈 김태웅입니다.
저번 포스팅
2. [삼성 SDS Brightics] 마블 수익에 장르가 영향을 끼치는가?(데이터 전.처.리.) 1편 <1차 개인 분석 프로젝트>
편에서
1. 개요 및 데이터 전처리
2. 분석 및 모델링
3. 시각화 및 레포트
중 ' 1. 개요 및 데이터 전처리 '를 살펴 봤습니다.
다음으로1. 개요 및 데이터 전처리
2. 분석 및 모델링
3. 시각화 및 레포트
그래서 이번 편은 1차 개인 분석 프로젝트의 두 번째 포스팅으로
'마블 수익에 장르가 영향을 끼치는가 - (2. 분석 및 모델링)
시작하도록하겠습니다.

여기서 잠깐 상관 관계, 다중공산성에 대해 간단히 말씀드리겠습니다.
우리가 회귀분석을 하고 분석한 모형이 적합한지를 알기위해서 내는 값들은 정말 많습니다. mse, r2, rmse 등등
그 중, 또 다른 첫 번째 방법으로는 (사실 엄연히 이건 전처리 과정이긴 합니다만) 독립변수 사이의 상관관계를 알아보는 방법이 있습니다. 상관계수가 너무 높다면, 변수를 제외 및 수정해야합니다. 왜냐? 우리는 '각 각의 독립변수가 종속변수에 미치는 영향'을 알아보는데, 각 각의 독립변수가 비슷한 자료면, 잘못된 모형이 도출되기 때문입니다.
둘이 비슷하여 설명력이 떨어진다.라고 생각하면 되겠습니다.
그라모 두 번째 방법은 바로 분석이 끝난 이후, 다중공산성을 보는 것입니다. 다중공산성이란?
회귀 분석에서 사용된 모형의 일부 예측 변수가 다른 예측 변수와 상관 정도가 높아, 데이터 분석 시 부정적인 영향을 미치는 현상을 말한다.
다중공선성 (naver.com)
결국 각 변수간의 상관 정도(계수)가 높아져서, 과정 자체가 유효해지지 않습니다. 그렇기에 변수를 제거하거나 수정해야 한다는 것.
(다중 공산성 = VIF)
앞서 상관관계와 다중공산성으 말씀 드린 이유는, 해당 값을 Brightics에서 제시 했지만, 제가 찾지 못하여. 파이썬으로 코드 치러 간 제 자신을 반성하기 위해서 입니다..
결국 파이썬으로 코드를 쭉 작성하다가 깨달았습니다.
Brightics는 항상 친.절. 하고 간.편. 하다.
항상 느끼지만 Brightics는 참 신기한 프로그램입니다. 내가 생각하는, 필요한 모든 것을 아래와 같이 말하며 준비 시켜두는 것 같습니다.
"ㅋ 야 임마 주인 너 이거 찾을 줄 알았어 ㅋㅋ 내가 이미 도출시켜놨어 마!"
이왕 이렇게 된거. Brightics와 편의성 비교를 위해 파이썬으로 짠 코드들 보여드리겠습니다.


※참고 회귀 방정식X, 공분산X, 다중 공산성X, 상관계수X 작성 안한 단순히 다중선형회귀 예측 모델과 기본 적인 검증※
제가 이걸 보여드린 이유는, 저 파이썬 잘해요~ 가 아닙니다.
Brightics는 항상 친.절. 하고 간.편. 하다.
를 강조하기 위해서입니다.
https://blog.naver.com/xodndxovnd/222797034080
3. [삼성 SDS Brightics] 마블 수익에 장르가 영향을 끼치는가?(다중선형회귀 및 일원배치분산분석) 2
장마가.. 장마가 끝났나..? 매미가 울기 시작하는가..? 급나게 더워부려쓰나..? 네 여러분 여름이 돌아왔어...
blog.naver.com
저의 재밌는 잡담과 세세한 이야기까지 듣고 싶으시다면 해당 포스팅 방문 부탁드리겠습니다.
1. 데이터 분석 및 모델링 (다중 선형회귀분석)
저번 시간에는 데이터 및 모델 불러오기, 전처리, 종속변수 Y(전 세계 매출) 값을
로그로 치환시켜서 보기 편하게 만드는 것까지 했습니다.
그렇다면, 회귀분석을 진행하기 전에
기초통계량 확인을 통해 추가적으로 변환할 변수들을 찾아봅니다.
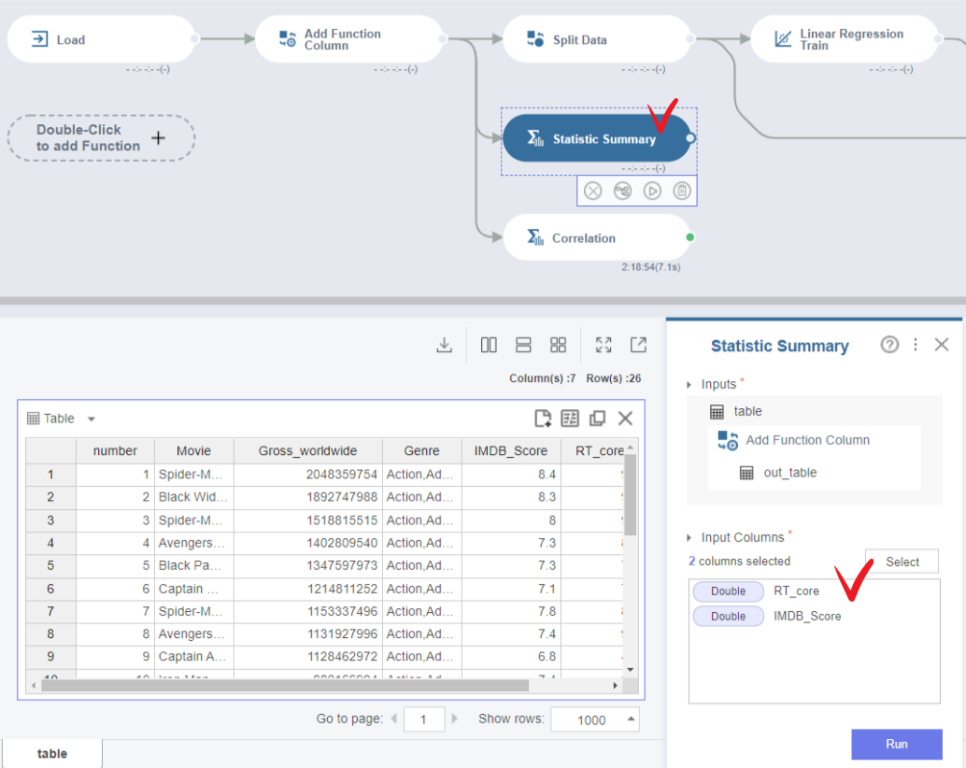
미니맵에서 Statistic Symmaty(통계량 요약)을 클릭해줍니다.
이후 오른쪽 아래 컨트롤 창의 Input Columns에 각각의 독립변수 RT_core, IMDB_Score를 넣어줍니다.
그리고 RUN.
※종속변수 Y는 이미 로그로 치환해 줬으니 제외시키고 봅니다.※

독립변수의 기초 통계량
이 비율적으로 봤을 때, 그리고 단위적으로 봤을 때 순서대로 최대값, 최소값, 평균, 분산, 표준편차, 1사분위, 3사분위
값들이 크게 차이나지 않기 때문에 더이상의 변환 없이 회귀분석을 진행해도 되겠다는 판단이 내려집니다.

미니맵에서 Correlation 함수를 선택합니다.
이후 오른쪽 아래 컨트롤 창의 Input Columns에
각각의 독립변수 RT_core, IMDB_Score와 종속변수 log_prc까지 넣어줍니다.
그리고 RUN.

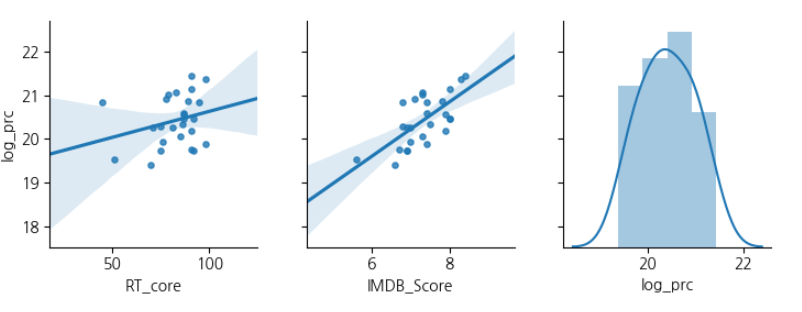

각 값들의 경우의 수들을 3*3 으로 그래프를 그려 보여줍니다.
오른쪽 아래로 내려가는 대각선에 위치한 칼럼차트는 단지 본인과의 상관관계를 나타내는 값으로, 1이 나옵니다.
이런 의미 없는 값을 알아보려한 것이 아니니, 그래서 테이블에서 보여주지도 않고, 그래프도 칼럼차트로 현황을 보여주고 있습니다.
왼쪽 아래 ㄴ자 3개는 X1-Y, X2-Y, X1-X2의 관계를 산점도와 직선으로 시각화 하여 보여준 것입니다.
그리고 오른쪽 위 ㄱ자 3개는 상관 계수를 나타냅니다.
자세한 상관관계를 구하는 이유는 위에 서술 했으니, 확인부탁드립니다.
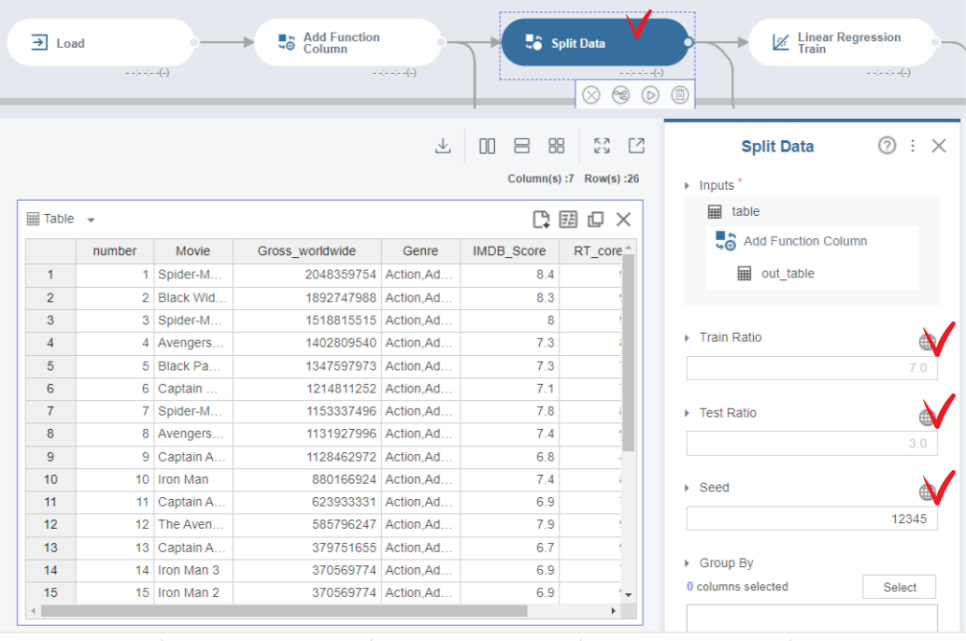
다중선형회귀분석 값을 내놓고, 예측까지 하기 위해서 우리는 학습 시킬 데이터와 학습시킨 모델의 평가를 통해, 잘 만들어졌는가? 하는 것을 확인해볼 수 있게, 데이터를 분할해야 합니다.
어떻게 보면 딥러닝이라고 보시면 됩니다. 간단한.
지금 제가 설정한 독립변수 RT_core와 IMDB_Score 값들을 컴퓨터에게 학습 시킨 후, 어떤 종속 변수 Y(전 세계 총 매출)이 나올지 도출시키는 것입니다. 이를 통해 회귀분석도, 예측 모델링도 함께 할 수 있습니다.
현재 종속변수 Y값을 줬으니 '지도 학습'이란 것을 시키는 것입니다.
그냥 정답과 학습시킬 값을 같이 주고 예측값을 뽑아내는 '모델'을 만드는 것은 '지도 학습법'
학습시킬 값만 주고 종속변수 Y를 진짜 예측해내는 '모델'을 만드는 것이 '비지도 학습법'이라 합니다.
해당 내용은 그냥 아~ 그렇구나~ 정도로 이해하고 넘어가시면 될 것 같습니다. 왜 학습 데이터와 테스트 데이터를 분리하는지 대강은 알아야 하기에 설명 드렸습니다.
미니맵에서 Split Data를 눌러주세요.
다음, 콘솔에서
Train Rario에 7.0
Test Ratio에 3.0
seed는 12345
를 기입해주세요.

앞서 가지고 있는 데이터를 활용해 학습을 시키는 지도 학습을 한다했는데, 위 그림을 보시면 대충 감이 올 겁니다.
Train Rario에 7.0은 모든 X값에서 70%는 학습에,
Test Ratio에 3.0은 모든 X값에서 30%는 평가용에,
seed는 12345는 그렇게 5개 시드로 뽑아봐라. 라는 의미입니다.
예측하려면 예측한 값이 올바른지? 를 확인하기 위해 데이터를 2개로 나누는 겁니다.
참고로 7:3이 대부분 사용하는 비율이고, 이는 프로그래머의 지정에 따라 달라집니다.

자 이제 대망의 '다중 회귀분석'을 해보겠습니다. 이렇게 장황하게 이야기한거 치고 간단합니다.
1. Linear Regression Train 클릭
2. columns selected에 독립변수 선택
3. Label column에 종속변수 선택
4. 나머지 건들지 말고, RUN.
위 과정을 파이썬으로 구현하면 아래와 같습니다.

심지어 +알파
다시한번 Brightics가 얼마나 편리하고 대단한 프로그램인지 느낍니다.
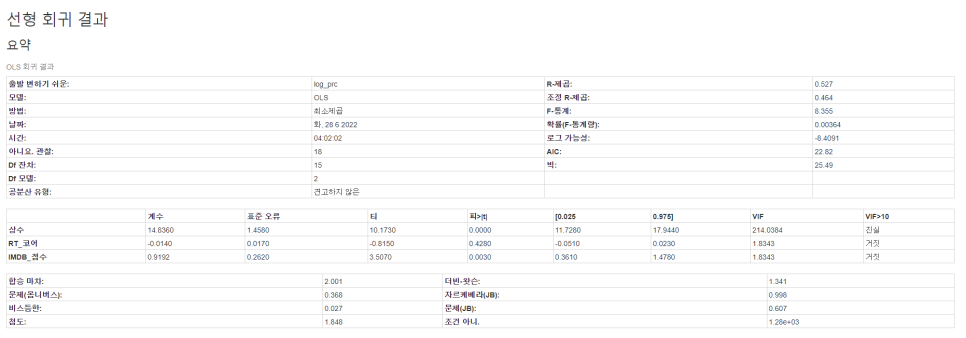
다중회귀분석 요약표입니다.

실행시키고 나면, 모델, 테이블 결과가 보여지는 창 오른쪽 맨 위에 나가기 표시를 클릭하세요.
요약표를 보니 R-squared : 0.527로 52.7% 준수한 설명력을 보여주고,
(대게 40%이상이면 유효한 설명력을 갖고 있다고 판단합니다.)
독립변수를 보니 IMDB_Score 는 p-value : 0.003 으로 0.01보다작아 유효하고,
RT_core는 p-value : 0.428로 0.05보다 큽니다. 유효하진 않지만. 일단 '타협'을 보고 진행합니다.
마지막으로 각 독립변수들의 VIF(다중공산성)이 1.8343으로 다중공산성이 없다고 판단할 수 있습니다.
(대게 10이 넘어가면 다중공산성이 있다고 판단하고, 유효하지 않은 변수 선정이라 판단합니다)
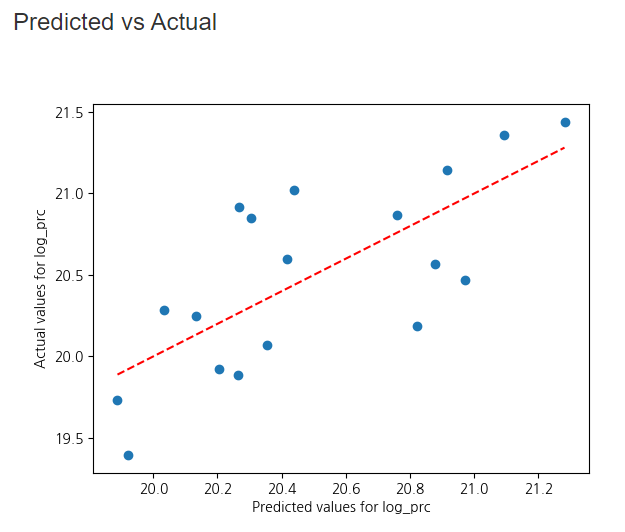
시각화 된 표를 보면, 예측 값은 빨간 점선으로, 실제 값(Y)들은 파란 점으로 찍혀 있는 것들을 볼 수 있습니다.

마지막으로 Fit Diagnostics 표를 보면
잔차 0을 기준으로 값들이 고르게 분포 돼 있어, 등분산성을 확인할 수 있고, 정규성에 가깝다는 것을 확인할 수 있습니다.
2. 모델 예측값 도출 (다중 선형회귀분석)

오늘의 마지막은 분석을 통해 만든 예측 모델을 실행시켜보는 것입니다.
이미 Inputs와 model이 미니맵의 드래그를 통해 해당 모델에 연결 돼 있는 것을 볼 수 있습니다.
그래서 다른 설정 안하고 RUN.

다중 선형회귀분석을 통한 예측 모델 구축, 해당 예측 모델을 통한 예측 값 도출이 완료 됐습니다.
3. 간단 후기
저는 사실 파이썬을 잘하는 편이 아니라 저 코드 찾아보고, 짜보고 하는데 몇시간이 걸렸습니다.
하지만
클릭 몇번에 엄청난 시간이 걸리는 분석과 모델 구축을 클릭 단 몇번, 30분 내로 끝낼 수 있게 해주는 갓 Brightics 그는...
그래서 그런 생각이 좀 듭니다. BrItics 미리 알았다면, 학교 과제는 다 이걸로하는건데. 프로젝트도 이걸로 값 먼저 확인할 수 있는거잖아? 보고서도 너무 잘나오고. 시각화도 자동이니 보고서 쓰기에 요만한 물건이 진짜 없는 것 같습니다.
지금이라도 알았으니 앞으로는 요긴하게 써야겠습니다. 너무 다행이라고 생각합니다.
오늘 말씀드린 부분까지 모두 완료했으니, 다음 시간에는
1. 개요 및 데이터 전처리
2. 분석 및 모델링
3. 시각화 및 레포트
3. 시각화 및 레포트를 작성해볼 시간입니다.
또한 회귀 모델의 평가도 간단하게 해볼 것이니, 올라오는 포스팅 확인해주시면 감사하겠습니다 :)
이상 자칭 데이터 분석 전문가(?) 삼성 SDS Brightics 3기 서포터즈 김태웅이었습니다.
※해당 포스팅은 Brightics 서포터즈 활동의
일환으로 작성 되었음을 알립니다.
'삼성 SDS Brightics 서포터즈 3기' 카테고리의 다른 글
| 6. [삼성 SDS Brightics] 팀 분석 프로젝트 2 텍스트 마이닝& 소비패턴분석 2차 팀 분석 프로젝트 (0) | 2022.08.23 |
|---|---|
| 4. [삼성 SDS Brightics] 마블 수익에 장르가 영향을 끼치는가?+수익 예측(모델 평가 및 레포트) 3편 <1차 개인 분석 프로젝트> (0) | 2022.07.07 |
| 2. [삼성 SDS Brightics] 마블 수익에 장르가 영향을 끼치는가?+수익 예측(데이터 전.처.리.) 1편 <1차 개인 분석 프로젝트> (0) | 2022.06.28 |
| 1. [삼성 SDS Brightics] 삼성 SDS Brightics 서포터즈 3기 발. 대. 식. (0) | 2022.06.25 |
| 삼성 SDS Brightics AI 설치 및 간단 사용기 (0) | 2022.06.18 |



