
안녕하십니까.
삼성 SDS Brightics 3기 서포터즈 김태웅입니다.
첫 티스토리 블로그 포스팅 '삼성 SDS Brightics AI 설치 및 간단 사용기'로 인사드립니다.
앞으로 올라오는 모든 삼성 SDS Brightics 서포터즈 활동에서 사용한 사용기의 간단 요약 버전을 업로드할 예정입니다.
담백한 내용을 보고 싶다면 해당 블로그를, 자세한 활동기와 입담을 확인하고 싶다면 아래
삼성 SDS Brightics, 웅버는 활동 중 : 네이버 블로그 (naver.com)
웅버는 활동 중 : 네이버 블로그
웅버의 대학 생활을 기록하는 블로그입니다. 빅데이터 분석가로 거듭나기까지!
blog.naver.com
네이버 블로그를 클릭해주시기 바랍니다.
1. 삼성 SDS Brightics AI / Studio 설치 방법
Brightics AI
www.brightics.ai
로그인 후, 위 사이트에 접속.

Brightics Studio 항목에서 본인 컴퓨터 운영 체제에 맞게 다운로드

다운 받은 파일을 실행, 설치 경로를 기입 후 Start 클릭
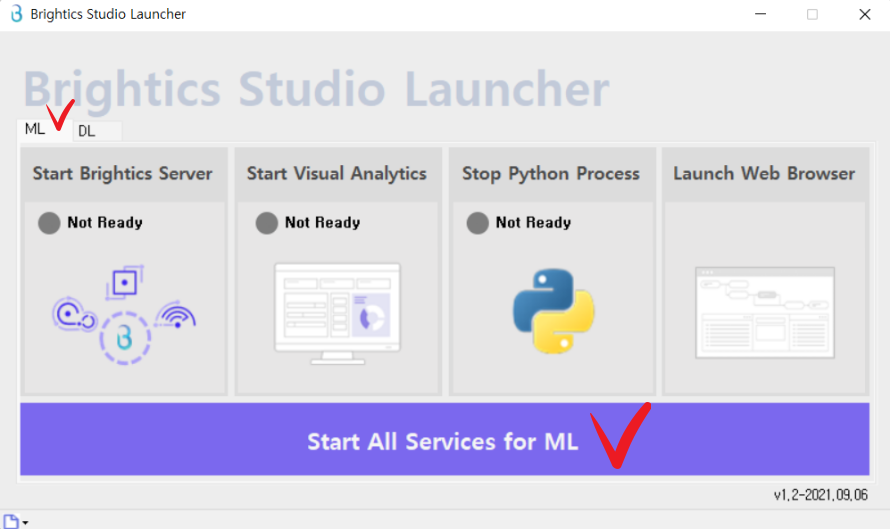
설치가 완료되면 해당 창이 뜹니다. 이때 ML(머신러닝), DL(딥러닝) 중 어떤 기법을 사용할지 체크하고
Start All Servies for ML/DL을 클릭해 줍니다.
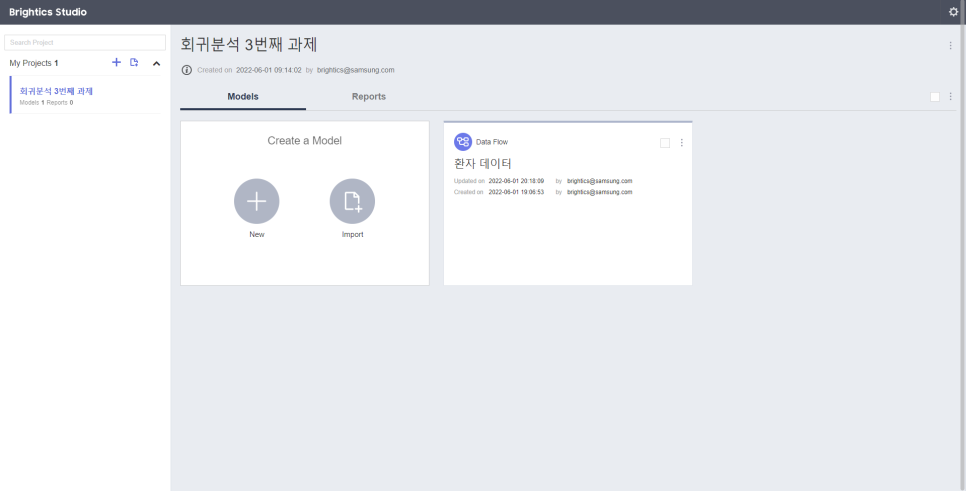
로딩이 끝나면, 위와 같은 창이 뜨며 설치 및 실행이 완료 됩니다.
2. 삼성 SDS Brightics AI / Studio 간단 사용기
Brightics Studio를 사용한 선형회귀분석을 진행해 보겠습니다.
불러올 데이터는 '환자 만족도' 데이터로 종속변수Y(환자 만족도), 독립변수X1(환자 나이)로 이루어져 있습니다.
즉, 독립변수인 환자 나이가 종속 변수인 환자 만족도에 얼마나 영향을 주나?를 확인하기 위해 단순선형회귀 분석을 진행합니다.
2-1. 데이터 불러오기
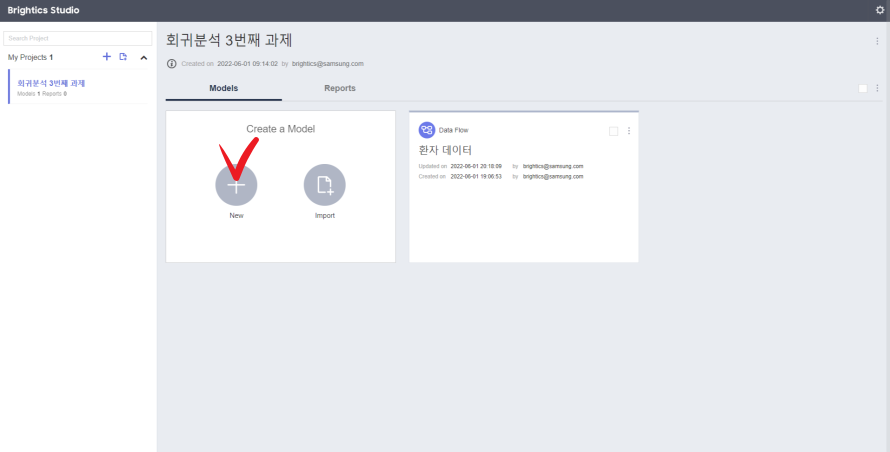
실행된 Brightics에서 모델 생성 (Create a Model)에 있는 +(New)버튼 클릭
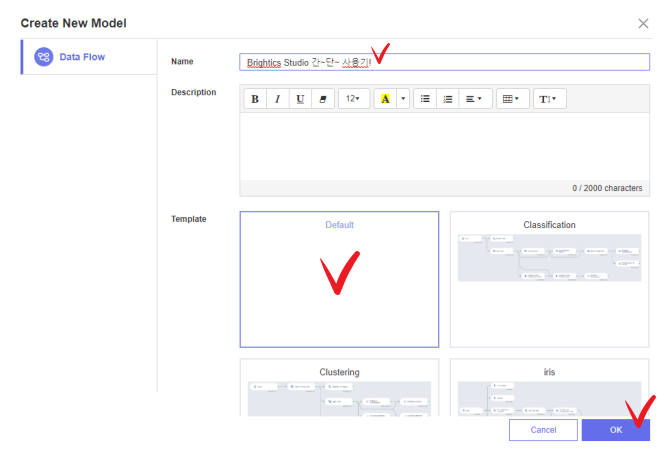
1. 다음으로 본인이 원하는 제목 작성
2. 템플릿은 Default로 두고
3. 마지막으로 OK 버튼 클릭

다음으로 기능 더하기(add Function)를 더블클릭
저는 데이터 입력의 편의를 위해 메모장(.TXT) 데이터를 불러왔습니다.
Load를 눌러 데이터를 불러옵니다.

Input Path를 누르면, 오른쪽과 같은 창이 뜹니다. 여기서 Add를 클릭

Local을 클릭하고, 데이터 파일을 불러와 주세요.

불러온 데이터의 행과 열, 그리고 네임을 지정해 줍니다. 텍스트 파일에 구성 돼 있는 데이터가 띄어쓰기로 돼 있어, Space를 클릭해줬습니다.

문자열, 순서, 척도, 명목형 등을 설정해 줍니다.
모두 설정 해 줬다면, 오른쪽 아래 Finish 버튼을 눌러줍니다.

왼쪽 아래 Run 클릭

해당 데이터 셋 불러오기가 완료 됐습니다.
2-2. 변수간 상관 관계 알아보기(함수 실행)
상관 계수를 확인해보며, 환자 만족도와 환자의 나이가 상관 관계가 있는지 먼저 알보겠습니다.
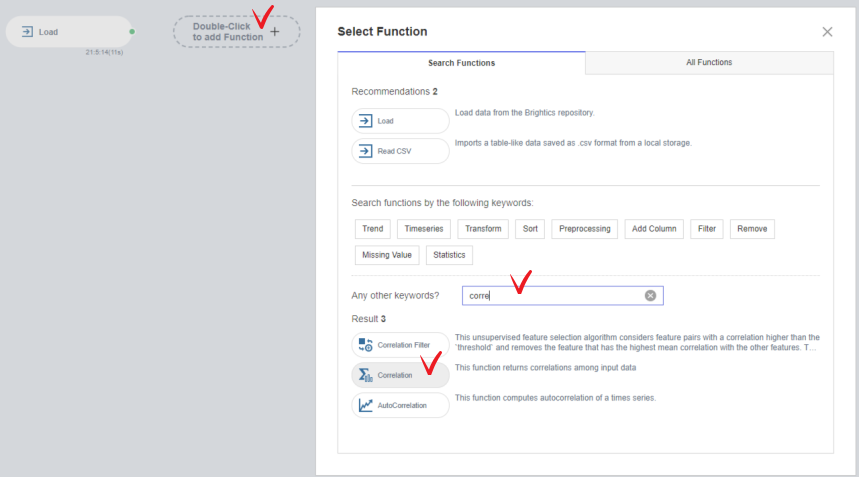
기능 더하기(add Function)를 더블클릭
corr를 검색
Correlation을 클릭 해줍니다.
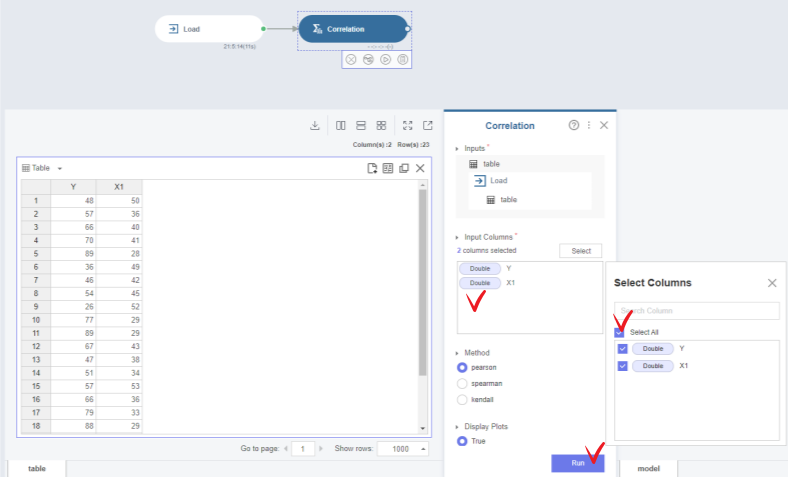
미니맵에 해당 함수가 생성된 것을 확인할 수 있습니다.
사용할변수들을 설정해주고, Run을 눌러 실행

해당 변수들은 서로 음의 상관 관계를 갖고 있으며, 계수는 -0.77로 높은 상관 관계를 가지고 있다는 것을 알 수 있습니다.

상관 계수, 유의확률(P-value)과 공분산(cov)까지 확인할 수 있습니다.
2-3. 단순선형회귀분석 실행하기

생성된 함 수 아래에 기능 더하기(add Function)를 더블클릭
linear을 검색 이후 Linear Regression Train을 클릭

Linear Regression Train이 미니맵에 등록됩니다.
그리고 Load 된 데이터에서 화살표를 꾹 누르며
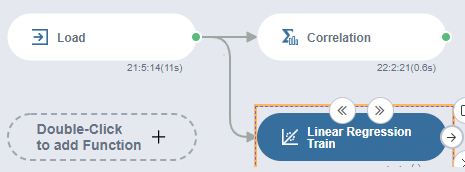
드래그하여 Linear Regression에 이어줍니다.

이후 생성 된 창에서 각각
columns selected 는 독립변수로 X1 데이터를 설정
Label column은 종속변수로 Y 데이터를 설정해줍니다.
마지막으로 Run을 클릭해 실행

R-squared 값을 보니 설명력은 0.599로 59.9% 준수한 설명력을 보이고 있습니다.
각 변수의 계수부터 표준오차, t-통계량, 유의 확률(P-value) 그리고 신뢰도 구간까지.
회귀분석을 실시할 때 알아야할 모든 정보들을 내포하고 있습니다.
해당 자료를 바탕으로 회귀 식을 작성하면 아래와 같습니다.
Y = 121.8318 −1.5270X1
유의 확률이 0.000..이므로 기각역은 따로 구하지 않아도
종속변수 Y(환자 만족도)의 변동에 독립변수 X1(환자 나이)이 유의한 영향을 끼친다.
라는 결과를 도출해 낼 수 있습니다.
상관 관계를 구하고, 시각화된 도표를 확인해보면 아래와 같고,

이는 나이가 오를수록 환자의 만족도는 떨어지고 있다는 것을 알 수 있습니다.
또 다른 증명으로 식에 x1값을 대입해 보겠습니다.
|
환자 나이 1살(X1)
|
환자 만족도(Y) = 120.3048
|
||
|
환자 나이 2살(X1)
|
환자 만족도(Y) = 118.7778
|
||
|
환자 나이 3살(X1)
|
환자 만족도(Y) = 117.2508
|
이상으로
삼성 SDS Brightics Studio를 사용하여 단순선형회귀분석을 실행해 봤습니다.
다음번에 Brightics Studio를 활용한 또 다른 실습 예제를 소개드리도록 하겠습니다.
감사합니다.
※ 해당 포스팅은 Brightics 서포터즈 활동의 일환으로 작성되었음을 알립니다.



