
안녕하십니까.
개인 분석 프로젝트 2번째 시간입니다.
주제가 조금 변경 됐습니다. 세부적인 입지를 선정하기에는 부족한 부분이 많아,
서울시 구별로 가장 급속 충전기가 필요한 곳을 먼저 알아보기로 생각했습니다.
첫 번째 시간에 이어 데이터 전처리 과정에 대해서 보여드리겠습니다.
더 많은 이야기들을 보고 싶다면, 아래 링크를 클릭해주세요.
https://blog.naver.com/xodndxovnd/222897332428
14. [삼성 SDS Brightics]1.(데이터 전처리) 서울시에 있는 주유소를 급속 충전소로 바꿔볼까? - (서울
안녕하십니까!!!! 개인 분석 프로젝트 2번째 시간으로 돌아왔습니다. 우선.. 문제가 많았어요 뭐냐구요? 너...
blog.naver.com
데이터 전처리
인구수는 충전소, 충전기에 절대적 영향을 미칩니다. 사람이 많으면 그만큼 차량이 많겠죠.
그래서 해당 데이터를 사용하도록 하겠습니다.
앞으로 모든 엑셀 데이터들을 불러올 때 이렇게 불어옵니다.
1. 대강 필요 없는 부분을 한 번 걸러주고
2. 다른 이름 저장 -> 텍스트 파일(탭으로 구분)
3. 텍스트 파일에서 모든 (" . , - _)기호 없애주기
4. 다른이름으로 저장 -> 인코딩:utf-8, 파일 제목 영어로 바꾸기
5. load하기.
자세한 내용은 바로 직전
해당 포스팅에 자세히 기입 돼 있으니깐 참고 부탁드립니다.
혹시 구분자나 기호 없애는거 모르시는 분을 위해 간단히 언급 드리고 넘어가겠습니다.

텍스트에서 편집 - 바꾸기를 눌러주세요.

그리고 바꾸고 싶은 기호를 적고, 아래 칸은 비워두고, 모두 바꾸기를 클릭해주면 전부 삭제 됩니다.

그러면 이렇게 문제 없이 파일이 잘 불러와 집니다.

여기서 저는 '구별' 행으로 나뉜 데이터들을 모을 겁니다.
구별로 어떤 변수들이 주유소 설립에 영향을 주는지 확인해보고,
여기 전기차, 충전기 등의 변수를 넣어 머신러닝을 통해
가장 많은 개수가 나온 자치구를 찾아볼 예정입니다.
구별 인구 통계가 필요하니깐 '나는'과 '계'라는 열이 필요합니다.
바로 select 함수를 활용해 두 변수만 선택,

그리고 이렇게 컬럼 명 또한 변경해 줍니다.
그리고 데이터에 이상이 없나 확인해 보기 위해 line 형태로 데이터를 확인해 줍니다.

항상 그렇듯 놓치는 이상치 값은 존재합니다. 두 번 세 번 확인하는 과정을 거쳐 분석 결과에 영향을 미치지 않도록 합니다.
소계값은 필요없으니 Filter 함수를 활용해 제거합니다.

행을 제거하는 방법은 없습니다. 밖에서 하고 오거나 해야하는 걸로 알고 있습니다.
그래서 Filter 함수를 사용하겠습니다.
데이터를 확인하면, 가장 인구가 많았던 송파구가 66만이니, 70만 이상은 모두 제거하도록 하겠습니다.

서울시 자치구 25개의 구별 인구 통계데이터를 가져왔습니다.
다음으로는

저번에 가져왔던 주유소 데이터를 사용해서, 구별로 주유소가 몇개 존재하는지 뽑아보겠습니다.

이번에도 select 함수를 할용해 구별로 이루어진 field 값만 가져옵니다.
그런데 전 인구 데이터랑 다른 점이 있습니다. 카운트가 안 돼 있고, 구 이름들이 나열 돼 있습니다.
그래서 Python Scrip를 활용해 구별로 몇개 있는지 확인해 봅니다.
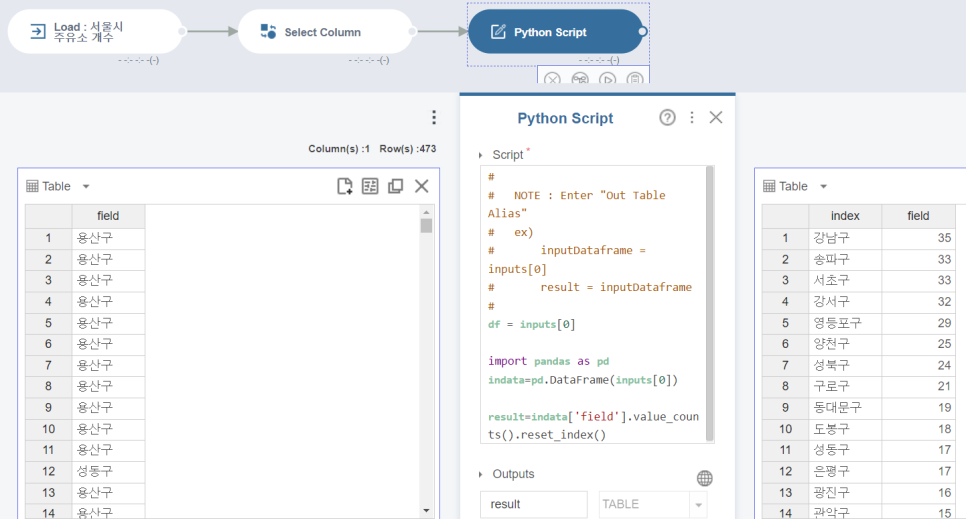
앞서 인구 통계 데이터 전처리와 같은 모양으로 변경 됐습니다.
사용한 코드는 아래와 같습니다.
df = inputs[0]
import pandas as pd
indata=pd.DataFrame(inputs[0])
result=indata['field'].value_counts().reset_index()현제 데이터를 데이터 프레임화 시키고,
그 데이터 프레임을 indata라 변수명을 지정합니다.
그리고 indata의 'field'컬럼들의 개수를 새는 value_counts, 행 값을 리셋하고, 카운트 한 해당 컬럼으로 중복을 하나로 줄이는 reset_index를 기입합니다.
마지막으로

꼭 Outputs 을 지정해준 마지막 데이터 변수명으로 적어주셔야합니다.
그렇지 않으면, 기존 데이터가 불러와 집니다.
https://data.seoul.go.kr/dataList/OA-162/S/1/datasetView.do
다음으로는 구별 화장실 개수 데이터를 살펴보겠습니다.
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr

개방 화장실 데이터입니다. 해당 데이터는 구 데이터가 없고, 좌표 데이터만 존재하여,
좌표를 주소로 바꿔주고, 불러왔습니다.

동일하게 select 함수를 활용하여 field 값만 가져오고,
Python Script를 활용해서 구별로 갯수를 새어 줍니다.
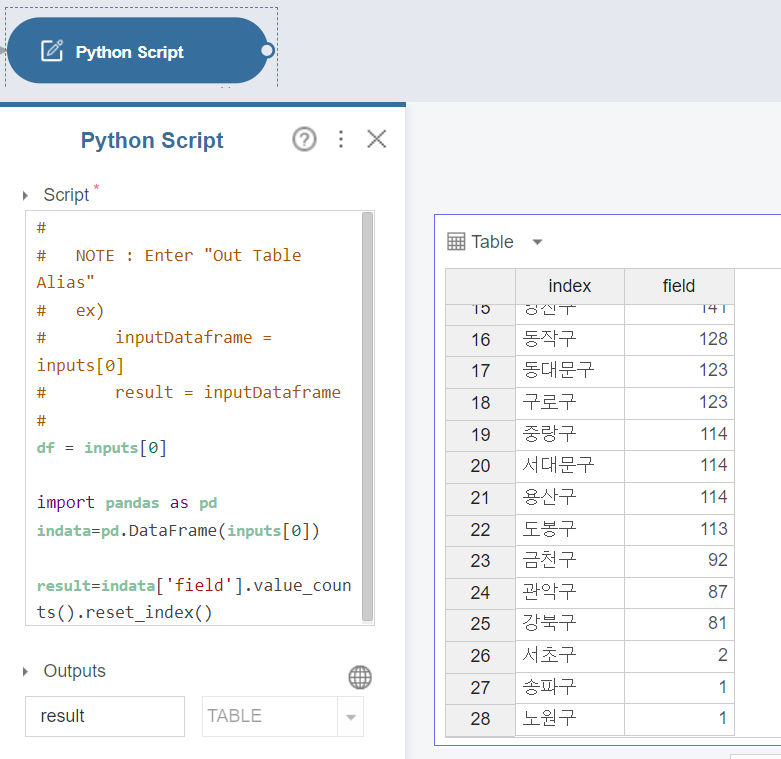
문제가 없을 때가 없군요.
데이터셋 파일을 열어보겠습니다.

사실 이전에 이걸 처리 했었습니다.
이게 지번, 도로명 주소 둘다 불러온건데, 둘중 하나가 누락된 데이터들이 존재했습니다.
그래서 서로를 보고 구를 따로 엑셀 MID함수를 활용해 빼고, 없는 데이터는 직접 손으로 적었는데 인식을 다른 글자로 인식을 했나 봅니다.
손으로 쓴거 결측치로 생각하고, 결측치 없애봅시다.

이렇게 미드 함수로 구 이름만 때오고,

필터를 걸어
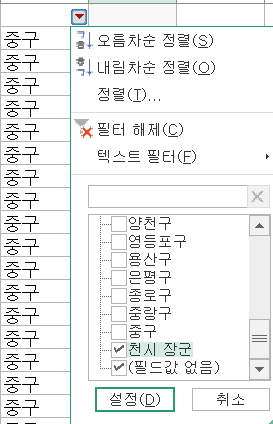
필드값 없음과 천시 장군만 설정하고, 행 자체를 제거합니다.
그리고 다시 데이터를 load하여 앞선 과정을 실행해 보면
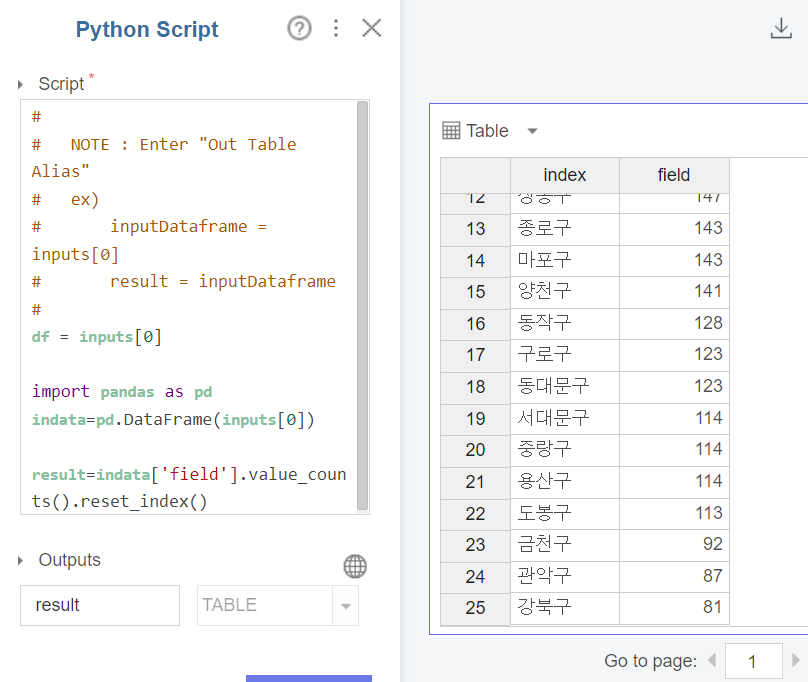
25개의 자치구별 화장실 갯수가 잘 뜨는 것을 확인할 수 있습니다.
이렇게, 여러분들 데이터 불러오실 때
'이상치와 결측치' 조심하셔야합니다!
이번에 알게 된 건데 숫자 결측치의 경우 nan이라 표시 되고,
Delete Missing Data 함수를 활용해 해당 행이나 열을 지울 수 있습니다.
하지만 왜인지 한글로 이루어진 파일이어서 그런지 해당 함수가 동작하지 않았습니다.
혹시 해당 내용에 대해서 알아오게 된다면, 추가적으로 언급하겠습니다.
다음주는 마무리 데이터 전처리와, 간단한 모델 구축 과정을 소개해 드리도록 하겠습니다.
※해당 포스팅은 Brightics 서포터즈 할동의 일환으로 작성되었음을 알립니다.



